За пределами CASE-технологий
или о
семантической стандартизации
метаданных.
Леонид Рейнгольд
Вместе с компьютерной техникой развиваются системы автоматизации разработки программного обеспечения для работы с данными.
Например, CASE - технологии предлагают нам все более совершенные методологические и программные средства для построения моделей окружающего мира и разработки необходимого прикладного программного обеспечения. Более подробно с различными методологиями этого направления и их практическими применениями можно познакомиться в перечисленной в конце статьи литературе на русском языке [1], [2], [3].
Возможно ли пойти еще дальше в плане формализации отражения процесса взаимодействия человека с миром?
Может быть возможна некая методология, позволяющая в перспективе обойтись без прикладного программирования в сегодняшнем понимании? Думается такое предположение реально.
Ниже рассматриваются некоторые подходы, позволяющие продвинуться в указанном направлении.
Объекты и показатели.
Окружающий нас мир может быть представлен как система объектов. Такими объектами являются люди и все, что их окружает: природная среда, жилые и промышленные здания, коммуникационная и транспортная инфраструктура и многое другое. Все они имеют те или иные взаимосвязи между собой.
Сейчас каждый анализ любого объекта уникален и ограничивается рамками приложения или группы взаимосвязанных приложений. Интерфейс для работы с информацией об объекте также уникален (за исключением общих соглашений об интерфейсе в применяемой ОС и особенностей применяемого средства разработки).
В то же время многообразие окружающей нас предметной среды имеет свои пределы. Имеющихся ресурсов типовых вычислительных средств становится достаточно для адекватного структурированного описания окружающей человека среды.
В развитие имеющейся методологии, определим понятие показателя, удобное в рассматриваемом контексте. Традиционно применяемые в технологиях моделирования понятия - атрибут, домен, свойство, метод, объект нуждаются в доопределении в нашем контексте.
Каждый объект и выполняемая им функция, интересующая нас, могут быть характеризованы набором показателей.
Под показателем здесь понимается существенная в рассматриваемом контексте характеристика объекта. Показатель – произвольный стандартизованный информационный элемент, отражающий структуру или поведение интересующего нас объекта.
Показатель может быть:
- числом,
- формализованным текстом,
- текстом в свободной форме,
- графическим или аудио элементом,
- программным модулем,
- результатом работы некоторого программного модуля.
То есть, показатель - комплексно и унифицировано описанный
любой элемент данных или операция над данными некоторого объекта. Причем при
представлении объекта в виде системы показателей, различия между атрибутами и операциями (действиями) над ними не
имеет принципиального значения. Операции - это тоже специфически
представленные показатели.
Показатель имеет традиционные признаки атрибута и дополнительные признаки:
|
традиционные признаки атрибута |
дополнительные признаки показателя |
|
формат |
унифицированный код |
|
маска для ввода и вывода |
единица измерения |
|
тип значения |
периодичность возникновения или изменения значений |
|
значение по умолчанию |
родительский (семантически) показатель |
|
… и другие признаки |
момент времени, в который показатель характеризует объект |
|
|
момент возникновения значения показателя |
|
|
источник значения показателя |
|
|
история значений показателя |
Дочерний показатель наследует семантические признаки родительского с их доопределением, при необходимости.
Например показатели размер->длинна->длинна автомобиля.
Всегда должна быть некоторая совокупность показателей, однозначно идентифицирующая данный объект в рассматриваемом его качестве среди других однотипных объектов.
Унификация показателя означает, что, однажды возникнув, он размещается в репозитарии, получает постоянный код и затем используется во всех случаях, когда его семантика соответствует требуемой (в границах доступности репозитария).
Каждый показатель для любого выбранного экземпляра объекта в каждый момент времени принимает некоторое значение.
Каждое значение показателя, которое сохраняется в системе, имеет некоторый момент (дату, время) возникновения. Можно говорить об истории значений показателя для данного объекта, если его значение меняется во времени. История значений показателя - одна из его характеристик.
Для получения системы показателей, характеризующих данный объект в интересующем контексте, может быть использована одна из имеющихся методологий структурного или объектного моделирования. При этом объект представляется как некоторый структурированный (например, в виде дерева иерархии) набор показателей.
Другими словами, показатели - унифицированные
по семантике, формату, единице измерения и условиям получения элементы описания
данных, по которым имеется возможность сохранения истории их значений в рамках,
определяемых уровнем доступности репозитария.
В качестве расширения общепринятых CASE - нотаций возможно включение в них средств описания моделей позволяющих отобразить интересующий объект в виде системы показателей. Конечным уровнем детализации модели должно быть построение взаимоувязанной системы характеризующих ее показателей.
При необходимости перестроить некоторое подмножество дерева показателей вследствие изменения представлений об объекте, такая перестройка, в принципе, формализуема и может быть выполнена автоматически, и касаться как структуры, так и значений показателей.
Для ввода в систему значений показателей и использования этих значений в различных целях, может быть разработан стандартизованный для данного типа объектов интерфейс.
Типология показателей.
Набор показателей специфичен для каждого вида объектов, однако возможно выделить их типологические группы. Наличие типологии показателей необходимо для проведения поиска, упорядочивания и анализа информации.
Некоторые основные типы показателей рассматриваются ниже.
Групповой и детальный показатели.
Имеются конкретные показатели, отражающие конкретное свойство, имеющие собственные значения, а есть объединяющие несколько других показателей в группу. Такие показатели будем называть групповыми. Групповые показатели наряду с конкретными показателями могут включать в себя другие группы.
Конкретный показатель может быть преобразован в групповой при возникновении потребности в более подробном описании объекта. Его значения, когда это имеет смысл, будут преобразованы к соответствующим осмысленным значениям в новой группе. Например, показатель, имеющий в качестве значений некоторый текст, может быть преобразован в группу показателей с делением текста на соответствующие фрагменты в соответствии с заданным алгоритмом.
Идентифицирующие показатели и информационные показатели.
Идентифицирующие показатели используются для
того, чтобы различать экземпляры интересующих объектов. Они должны быть
достаточны для однозначной идентификации объектов в рассматриваемой области
применения.
К ним могут относиться унифицированный код показателя, дата-время ввода значения показателя, ссылка на источник значения показателя.
Система идентификации показателей должна быть глобальной для данного типа объектов и иметь, при необходимости, средства для преобразования существующих локальных систем идентификации в глобальные.
Статические и динамические (поведенческие) показатели.
Показатели подразделяются на показатели, отражающие структуру объекта и характеризующие его изменение. Показатели, характеризующие изменение объекта, могут, как принимать конкретное значение, так и быть реализованными тем или иным способом алгоритмами, программная реализация которых является значением соответствующего показателя.
Мультимедиа показатели.
Значения показателей могут быть произвольными двоичными данными, в том числе содержащими аудио и видео информацию. В случае более детального структурирования соответствующего значения они могут быть представлены в виде группы, содержащей более детальные значения.
Шаблоны показателей и показатели объекта.
Одни и те же показатели и их группы могут и должны использоваться при описании различных объектов. При этом важно, чтобы однотипные показатели могли использоваться в различных типах и экземплярах объектов.
Поэтому представляется важным построение общедоступных репозитариев показателей и их устойчивых групп, которые бы обеспечивали совместимость данных, даже если это изначально не предусматривалось.
Если возникает новый показатель или их группа, то они вносятся в репозитарий. Если новый показатель получен преобразованием из локальной системы, то в репозитарии помещается также алгоритм его преобразования в локальный показатель и обратно.
Шаблоны показателей являются основой для построения совместимых массивов данных. Совместимость может быть двух основных типов: совместимость на уровне кодов и семантическая совместимость. Если проблема совместимости кодов технически ясна - это хотя и технически сложная, но вполне разрешимая проблема, то обеспечение семантической совместимости требует дополнительного исследования.
История показателей.
Значение показателя всегда возникает как характеристика
некоторого конкретного объекта в данный момент времени. Как
минимум два момента времени должны быть зафиксированы в базе данных значений
показателей.
1. Момент времени, в который данное значение характеризует объект.
2. Момент ввода значения показателя.
Другой важной характеристикой значения показателя, важной во многих случаях является информация об источнике для данного значения показателя. Понятно, что для ряда объектов одно и то же значение для того же показателя может возникнуть в разное время и из различных источников.
При этом подразумевается, что источник данных - такой же объект, как и другие, его структура и значения показателей описаны в базе данных значений показателей, соответственно ссылка на него -неотъемлемый признак значения показателя.
То есть, другими словами: в данной концепции предполагается,
что каждое значение показателя в репозитарии значений показателей
может иметь несколько значений, возникших в разное время и из различных
источников.
Например, количество солдат в армии конкретной страны в конкретной войне в конкретном году может быть приведено с позиций различных конфликтовавших сторон, различных организаций внутри этих стран, и меняться с течением времени. При этом все эти значения (в том числе и устаревшие, замененные более новыми) имеют право на существование.
Особенности показателей.
Основные отличия показателей от свойств и методов объектов, принятых в объектной технологии программирования, следующие:
- они имеют унифицированное и доступное заданному кругу лиц (в общем случае всем пользователям сети) описание;
- они имеют историю значений;
- они имеют историю структуры;
- в необходимых случаях история показателей может отчуждаться от источника сведений;
- могут применяться хранящиеся вместе с их описанием унифицированные интерфейсы для работы с показателями и их группами для ввода и модификации значений показателей для экземпляров объектов, анализа данных.
То есть значение показателя – это не просто некоторое число или строка, а значение, содержащее необходимую информацию о собственной семантике.
Типовые модели объектов
Окружающая нас действительность включает различные объекты, часть из них представляет первоочередной практический интерес.
Каждый объект может быть описан системой унифицированных показателей. Возможно построение типовых моделей объектов, обобщающих свойства похожих конкретных объектов. Имеется два основных подхода к построению таких типовых моделей.
Первый подход - это создание необходимых формализованных описаний интересующих объектов реального мира на основе некоторых методологических предположений, второй - реинжениринг имеющихся наработок (как в плане структур данных, так и в плане имеющихся модулей программного обеспечения, обеспечивающих необходимую функциональность). Заключительный этап реинжениринга - конвертация имеющихся данных в новую схему, позволяющую работать в рамках новой методологии.
Для построения типовых моделей объекта необходимы последовательные описания и классификация интересующих объектов с необходимых точек зрения. Это описание должно включать в себя сведения, обеспечивающие идентификацию объекта в нужном контексте, а также структурные описания, детализирующие различные точки зрения на него. Например: общая характеристика объекта, изготовление объекта, различные способы использования объекта, маркетинг объекта.
Система должна включать средства, позволяющие осуществлять идентификацию данного типа объекта и увязку различных его моделей, с учетом возможного пересечения данных различных моделей. Пересекающиеся данные одной модели должны автоматически использоваться другой моделью.
Наличие типового описания объекта позволяет применять типовые же средства работы с данными об этом объекте. В том числе типовые элементы управления для манипулирования информацией об объекте - для ввода и модификации данных, поиска, анализа информации. То есть вместе с описанием данных хранятся крупноблочные фрагменты приложений для работы с ними, не требующие сложного программирования при их настройке и использовании. Такие фрагменты просты для восприятия пользователем, поскольку относятся к конкретным данным.
Следует отметить, что в рамках рассматриваемого подхода не ограничивается возможность альтернативного описания для отражения одних и тех же точек зрения на объект. В то же время, на мой взгляд, существующим CASE-технологиям присущи недостаточные возможности по отражению возможной альтернативности действительности. Представляется необходимым доработка средств для адекватного отражения альтернативности в структуре модели и построения соответствий между альтернативными и семантически пересекающимися описаниями объектов.
Поскольку объект претерпевает изменения во времени, изменяются как значения описывающих его показателей, так и структура его описания.
Изменения объекта характеризуются временными рядами значений показателей, составляющих описание объекта.
Изменения в структуре описания объектов меняют структуру временных рядов значений. Изменение структуры описания не влечет за собой потерю значений, полученных в старой структуре, поскольку история значений дополняется историей изменения структуры объектов.
Теоретически возможна бесконечная и максимально детальная история, хотя в действительности она, конечно, будет формироваться в пределах концептуально заданной точности.
Возможен знаменательный момент в истории
человечества - появление подробной истории всего существенного, что нас
окружает.
Это история государств и события в жизни отдельных людей, строений, выдающихся механизмов и машин, любых природных. История искусственных и виртуальных объектов, событий социальной и политической жизни, формализованная, поддающаяся любому анализу.
Каждый объект, когда-либо возникавший на Земле
и кого-либо заинтересовавший (природный, биологический, артефакт, информационный
объект) будет оставлять свой след в структурированной компьютерной памяти.
Чем интереснее объект людям, тем более изменчиво будет его описание. Естественно ожидать и что детальность описания будет увеличиваться со временем.
Описание каждого объекта должно включать первичный ключ, идентифицирующий его в ряду подобных независимо от точки зрения на него и источника информации. Должен также появиться механизм разделения значений показателей для объектов и их слияния в случае ошибок или несоответствий в их идентификации.
Необходимы репозитарии, обеспечивающие накопление и распространение метаданных содержащие:
- каталог описаний показателей;
- каталог типовых объектов описанных унифицированными показателями;
- базы данных значений показателей для экземпляров объектов (факультативная, но во многих случаях естественная функция для репозитария метаданных).
Репозитарии и базы данных значений показателей по уровню общности и принадлежности описанных в них объектов могут быть:
- надгосударственные;
- государственные;
- частные нотариальные;
- корпоративные;
- личные.
Ничто не мешает репозитариям разного уровня взаимодействовать в целях построения совместимой инфраструктуры метаданных.
Наличие репозитария - сильный стимул к семантической и функциональной стандартизации описаний окружающей человека среды. Дополнительный смысл репозитария во многом - отчуждение информации от источника этой информации. Источник данных не сможет произвольно менять структуру описания метаданных и данные, полученные с их помощью с потерей информации и совместимости с предыдущими версиями данных. Для некоторых приложений это важно.
Эпоха "всеобщей памяти" будет порождать новые проблемы - философские, морально-этические, юридические, психологические, экономические. Другая проблема - проблема достоверности, отсутствия искажений в данных и их описаниях. Она имеет технический, математический, организационный, социальный аспекты. Их рассмотрение выходит за рамки этой статьи.
Необходимы механизмы, позволяющие верифицировать информацию, разграничить к ней доступ, чтобы максимально защитить интересы отдельных людей и их объединений. Это опять таки легче осуществить и проконтролировать в рамках унифицированной, концептуально последовательно разработанной среды, доступной для реализации различных демократических механизмов контроля.
Структурирование действительности
В связи с тем, что значительная часть имеющейся информации
накоплена человечеством в виде связного текста, а связный текст удобен для
восприятия, то можно предположить появление технологий
автоматизированного структурирования текстовых описаний объектов и наоборот -
построения текстовых описаний из структурированной системы.
Вообще говоря, сложность существенных сторон
окружающего нас мира конечна, поэтому конечна и сложность системы показателей и
их значений, которые необходимы для их описания.
Возможна приведенная ниже общая схема структурирования интересующих аспектов действительности.
1. Универсальная семантическая классификация и структурированное описание объектов реальной действительности.
2. Выявление набора существенных в практике точек зрения (контекстов рассмотрения) на каждый интересующий тип объектов.
3. Построение модели объекта на основе описаний типовых объектов и дополнительных показателей, характеризующих объект.
4. Разработка типовых методов взаимодействия с объектом данного типа и в данном контексте - например, создание экземпляра объекта данного типа и заполнение его данными, поиск и анализ информации о подобных объектах.
В рамках данного подхода одна из основных функций государства в перспективе – депонирование данных о входящих в его компетенцию объектах и предоставление доступа к ним гражданам и организациям с учетом установленного нормативными документами разграничения доступа и других факторов. К ней могут быть сведены многие различные, на первый взгляд, управленческие и контрольные функции.
Во многих случаях управленческие воздействия – результат простого преобразования исходных данных. Такое управление может быть реализовано в репозитарии данных в автоматическом режиме.
Работа с объектами.
Изложенное ранее может быть проиллюстрировано приведенной ниже схемой. Описание структуры и поведения объекта служит основой для формирования базы данных значений показателей, описывающих каждый экземпляр объекта. При этом каждое значение показателя имеет историю, как по структуре, так и по значениям и не является закрытым для ввода новой информации, поскольку всегда привязано к некоторому источнику.
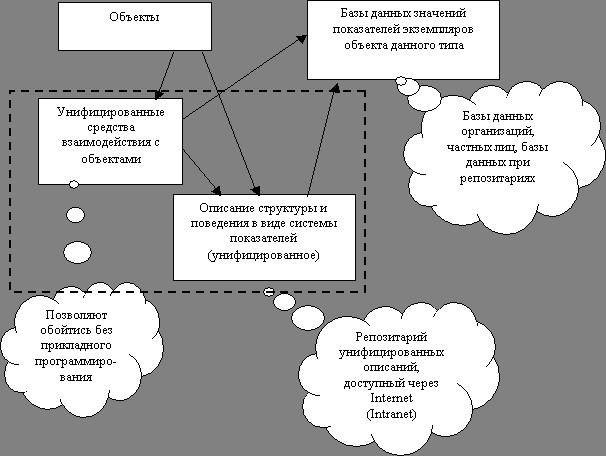
Предлагаемый подход позволяет накапливать непротиворечивые структурированные данные по любой тематике.
При усложнении или преобразовании системы в более сложную данные не будут потеряны. Они будут автоматически трансформированы в новую модель или останутся в истории состояний данного объекта рамках прежней структуры.
Подход к структурированным данным и технологии их обработки как к глобальному ресурсу требует нового подхода к проектированию интерфейса, поскольку интерфейс не является фиксированным и меняется в соответствии с запросами конечного пользователя. Интерфейс RAD и тем более командный интерфейс представляются слишком сложными для этой цели.
Необходим интерфейс для работы со
стандартизованными описаниями показателей, доступный конечному пользователю и
обладающий необходимой функциональностью.
Многие необходимые, но малопонятные пользователю элементы описания могут быть скрыты от него. Значения по умолчанию могут поступать из репозитария показателей.
Возможно появление специфической
RAD–технологии, по своей сложности в существенной мере доступной конечному пользователю
с ее поддержкой через репозитарий, находящийся в сети.
Для решения такой задачи на уровне конечного пользователя, возможно лучше всего подойдет, например, манипулирование объемными графическими моделями объектов, которое больше напоминало бы игру, чем построение или подгонку для себя интерфейса конечным пользователем.
Нужно отметить, что предлагаемый подход не
отрицает возможности использования различных альтернативных вариантов в реализации интерфейса для работы с одними и
теми же типами объектов.
СУБД и предлагаемая методология.
Предлагаемый подход, по мнению автора, накладывает свой отпечаток на методологию СУБД.
Понятно, что сейчас логично ожидать качественного скачка в развитии СУБД. Объективно его не может не быть в эпоху, когда 20 GB памяти прямого доступа стоят $200 и на столе каждого пользователя стоит супер-ЭВМ недавнего прошлого. Естественным в этих условиях будет увеличение возможностей по отражению в компьютерных системах того, что нас окружает.
То, что происходит вокруг нас, происходит в определенной исторической последовательности. Наши представления об окружающей среде также имеют свою историю, уточняясь и изменяясь в соответствии с текущими потребностями и представлениями.
В то же время методологии, используемые при проектировании баз данных и приложений для работы с ними фактор времени непосредственно не учитывают.
Так, например, объектная методология без учета истории объектов концептуально неполна. Она отвечает решению сиюминутных задач, но не отражает генезис объекта.
Часто заранее неизвестно, каким образом данные
будут использованы в будущем. Поэтому
желателен унифицированный механизм, обеспечивающий увязывание данных на
семантическом уровне, уровне кодов классификаторов и во временном разрезе.
Подход к решению этих задач возможен в рамках рассматриваемой методологии.
При ее использовании возможна разработка СУБД, имеющей встроенную поддержку историй структур данных и значений данных. В современных же СУБД словарь данных и собственно база данных содержат только данные о текущем состоянии структуры базы данных и значений экземпляров данных и не содержат средств ведения их истории.
Приложения, требующие в той или иной степени, поддержки истории данных, в том числе в разработке которых приходилось участвовать автору, получаются очень громоздкими и сложными в сопровождении, как на системном, так и на прикладном уровне.
Назовем СУБД, лишенные перечисленных выше недостатков СУБД с абсолютным запоминанием (absolute memorize DBMS - AM DBMS). Такая СУБД будет запоминать историю собственной структуры и все прошлые значения данных. Может быть, даже иметь механизмы, гарантирующие неизменность прошлых значений как за счет встроенных в ядро базы данных соответствующих механизмов, так и за счет распределенного хранения данных. Естественно должны иметься средства для управления формированием встроенной истории. Момент возникновения значения истории показателя - момент завершения транзакции, фиксирующей в базе данных следующее его значение. Хотя возможны и другие условия возникновения истории значений показателей.
Очевидно, такая СУБД может быть реализована на основе имеющихся средств. Имеющиеся в СУБД средства протоколирования могут использоваться для построения истории на основе различных событий, происходящих при изменении базы данных, но они не являются готовым решением для рассматриваемой задачи. Принципиально более эффективной может быть ее специальная реализация. Она, в частности, должна включать в себя:
- различные режимы доступа к истории;
- возможность назначить группы объектов, для которых ведется история и режим ее ведения (в том числе и полная история всех объектов базы данных);
- расширенную концепцию словаря данных, включающую историю структуры и репозитария показателей;
- механизм разграничения доступа к истории;
- дополнительные средства эффективного хранения новых типов данных;
- расширенный язык запросов на необходимых уровнях (традиционного языка запросов SQL и надстроек над ним, обычно встроенных в ядро и средства разработки приложений СУБД - недостаточно);
- возможности взаимодействия с внешними репозитариями показателей;
- встроенные средства для предотвращения изменения истории данных.
Если в такой СУБД режим предотвращения изменения истории старых данных включен, то старые данные изменять нельзя без того, чтобы оставить следы этого в той или иной форме. В радикальном случае возможна даже утрата работоспособности копии базы, в историю которой были внесены изменения. То есть изменение истории может означать откат базы к последнему достоверному состоянию. Для реализации этого положения могут быть использованы технология шифрования с открытым ключом и другие варианты защиты разрабатываемые, в частности, для систем электронной коммерции.
Возможна разработка принципиально новых механизмов, которые никак не реализованы в применяемых СУБД. Например, поддержка транзакций при изменении структуры объекта.
СУБД с неудаляемыми данными могут оказаться весьма эффективны при специальной реализации. Поскольку данные при этом могут быть представлены более компактно, не требуется их реорганизация в процессе работы.
Предлагаемый подход повлечет за собой изменения в реализациях технологий клиент-сервер, повсеместно использующихся в различных вариациях в настоящее время.
Несколько утрируя, можно предположить, что в целом предлагаемый подход при построении приложений позволяет перейти от
компонентного проектирования на уровне элементов форм на уровень
проектирования, где элементом является группа форм, обеспечивающая работу со
структурированными, стандартизованными агрегатами данных.
На приведенной ниже схеме приводится один из возможных вариантов такого изменения. Более подробное рассмотрение этого вопроса выходит за рамки этой статьи.
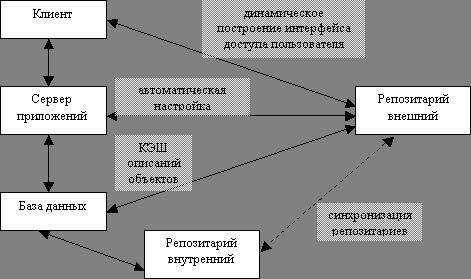
Internet и предлагаемая система.
Результатом практического внедрения системы станет появление новой Internet - технологии. Она будет включать поддержку репозитария объектов и их описаний, а также механизмы, обеспечивающие работу с ними.
Этот сервис может быть достаточно универсален. Один и тот же объект на разных уровнях декомпозиции может быть виден по-разному, с разных точек зрения, в частности возможны: взгляд системного аналитика, конечного пользователя системы, разработчика информационных систем. Каждый тип пользователя репозитария будет иметь свой уровень доступа к нему как по составу доступных функций, так и по возможностям использования и изменения объектов репозитария.
Объектная модель среды, окружающей человека может быть доступна, например, через интерфейс Web. Работа с ней будет включать:
1. Выбор объекта и контекста его рассмотрения.
2. Выбор подмножества интересующих характеристик объекта.
3. Получение данных в интерпретированном виде.
4. Получение, при необходимости, данных в первичном виде для последующего анализа.
Изложенное выше означает возможность появления нового сервиса в Internet «структурированный Web» со своим интерфейсом, средствами настройки, системой доступа и программирования.
Такой сервис будет изначально направлен в отличие от обычного Web-сервиса не на произвольный текст, а на работу со структурированными объектами.
Заключение
Автор надеется, что описанные в статье может быть не бесспорные концептуальные положения, послужат цели осмысления возможных направлений технологического развития в области компьютерной технологии и основой для плодотворной дискуссии по затронутым проблемам.
Предлагаемая методология может потребовать больших ресурсов памяти и производительности. Однако беспрецедентный рост объемов памяти носителей, скорости работы массовых процессоров и возможностей коммуникации компьютеров неизбежно должен иметь качественные последствия. Может быть одним из таких последствий станет внедрение предлагаемой методологии.
Возможность появления истории в компьютерных данных на самом общем методологическом уровне имеет, на мой взгляд, достаточно существенные последствия в различных сферах жизни человека.
В качестве примера на самом общем социальном и философском уровне можно отметить концептуальное исключение возможности возникновения в будущем на базе компьютерных технологий "министерства правды" оперативно переписывающего историю в соответствии с пожеланиями действующего высшего руководства - страны, корпорации и еще чего-либо, в духе описанного Оруэллом в романе "1984". В самом деле, бумажные носители уже сейчас в значительной степени вытесняются Internet - технологиями. А каждый Web-узел - "министерство правды" в миниатюре, данные в котором могут меняться произвольно в зависимости от конъюнктуры. Автору известны такие примеры.
Вполне возможно, что наши потомки будут знакомиться с нашей жизнью не только по фотографиям, фильмам и старым открыткам, но и по структурированным данным, хранящимся в базах данных с поддержкой истории.
[1] UML в кратком изложении. Применение стандартного языка объектного моделирования: Пер. с англ.-М.:Мир, 1999.-191 с.,ил.
[2] Г.Н.Калянов. Консалтинг при автоматизации предприятий: Научно-практическое издание. Серия "Информатизация России на пороге XXI века".-М.:Синтег, 1997.-316 с.
[3] Маклаков С. В. BPwin и ERwin. CASE-средства разработки
информационных систем.-М.:Диалог-Мифи, 1999.-295 с.